
研究背景:
对于一张低光图像,不仅是暗,而且也会伴随着噪声和颜色失真等多方面的图像功能退化,所以仅仅提高亮度将无可避免的提高人工产生的影响,必然会放大隐藏的伪影
特点:
还是从retinex理论中得到的启发,继而将弱光图像分解为光照(illumination)和 反射率(reflectance);前者负责亮度调整,后者用于去除降质(噪声,颜色失真)。这样图像分解的好处是让每一个模块可以更好地被正规化/学习
而对于输入图像,该网络只需要使用两张不同曝光条件下的图像(即使他们是两张弱光图像也可以),而不是弱光图像和真实图像(这样的好处是,很难定义多亮的图像算是真实图像)
对于严重的视觉缺陷图片也依旧拥有很强的鲁棒性
效果:
模型在2080Ti下的训练速度为,处理一张VGA分辨率图片花费的时间不到50ms
用户可以自由的调节光照水平(暂时没看到在哪体现)
具体效果展示(实机测试):
不同噪度:
高光图像和低光图像对照(不同的)

可以得出,KinD在多条件下,效果暂时都优于其他低照度优化算法(最主要的是效果真实,相较于其余算法,失真的情况会大大减少(不过现在还有一个KinD++))
解决问题
- How to effectively estimate the illumination component from a single image, and flexibly adjust light levels?
如何从单个图像中有效地估计照明分量,并灵活地调整亮度?
- How to remove the degradations like noise and color dis- tortion previously hidden in the darkness after lightening up dark regions?
如何消除黑暗和因为黑暗而隐藏的色彩失真?
- How to train a model without well-defined ground-truth light conditions for low-light image enhancement by only looking at two/several different examples?
如何仅通过查看两个/多个不同的示例,在没有明确的ground-truth光条件的情况下训练模型以进行微光图像增强?
差异
相较于之前我们所见到的Retinex-net,其在分解图上的观点有所不同,Retinex-net认为在不同照度下,共享一致的反射率,而KinD的理论认为,在不同照度条件下,反射图是不同的,因为弱光图像会在黑暗中退化(或者说越是黑暗退化越严重)这种退化被转移到了反射图中,就造成了信息的丢失,而在(相对)明亮的图中的反射率可以作为退化弱光图像的参考(ground-truth),所以我认为,该网络还学习了反射图的退化(优化点)
网络结构
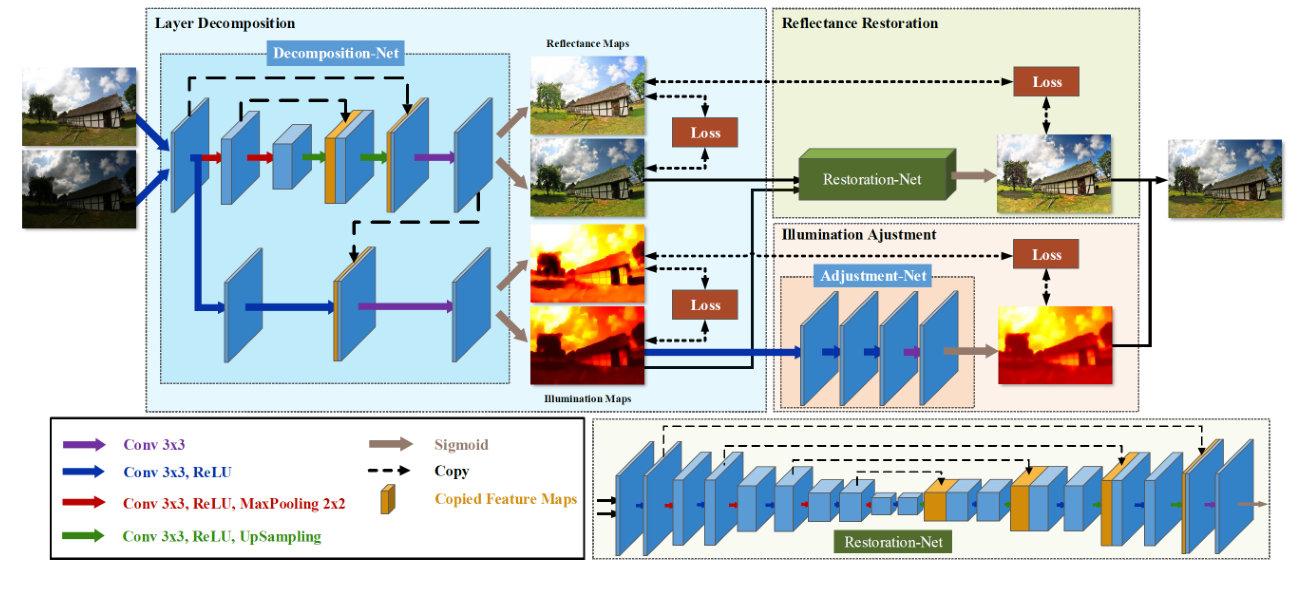
Illumination Guided Reflectance Restoration(光照引导反射恢复)
从数学上来讲,对于一张图片应该被表现为:
其中 E 被表现为退化的部分
经过一些数学的代数方法,可以表示为:
其中$ \tilde{\mathbf{R}} \tilde{\mathbf{E}}$表示光照解耦的退化
PS:反射率 reflectance 的恢复不能在整个图像上进行均匀处理,而光照图 illumination 可以作为一个很好的向导起到指引作用
不从弱光图像中直接去除噪声的原因:1.失衡问题仍然存在,图像中的细节和噪声混在一起 2.去噪没有合适的参考图像
Arbitrary Illumination Manipulation(获得任意光照条件下的图)
不同的情况可能需要不同的图,实际系统需要为任意照明操作提供接口,在各个文献中,增强光照条件的三种主要方法是聚变、光级指定和伽马校正。由于固定的融合模式,基于融合的方法缺乏光线调节功能。如果采用光级指定,训练数据集必须包含具有目标级别的图像,这限制了其灵活性。对于伽马校正,虽然可以通过设置不同的伽马值来实现目标,但它可能无法反映不同光线(曝光)水平之间的关系。本文提倡从真实数据中学习灵活的映射函数,该函数允许用户指定任意级别的光照/曝光。
网络内部
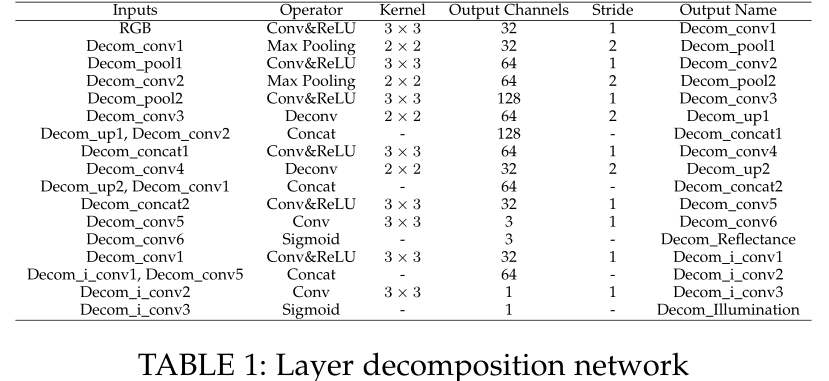
Layer Decomposition Net
损失函数的定义(借鉴博客):
- reflectance similarity :对于强光图像和弱光图像,二者的反射率是近似相同的(如果不考虑退化的话),因此将反射率正则化的损失函数定义为:
- illumination smoothness :前面分析过,光照图像可以用输入图像进行引导,在输入图像强边缘区,光照发生较大变化;在弱边缘区,光照可以认为也是平滑的,因此损失函数定义为:
注意到,当大时(边缘),使得损失函数值很小,此时对 的约束较轻;当较小时(平滑),使得损失函数值增大,此时要求必须很小,才能减小损失函数值。这样,光照图像就和输入图像 有一个相关的结构
mutual consistency :定义为
(这里有点不理解原理,真的不太明白它的意思,大概就是迫使迫使其中一个和另一个相近)
reconstruction error :即生成的反过来合成的两个新图,应分别 与相似,即
图层分解网络的结构:
reflectance branch :5-layer U-Net + a conv layer + Sigmoid ;
illumination branch :two (conv+ReLU layers) + a conv layer(级联从 reflectance branch 来的特征图,目的是为了从光照中排除纹理)+ Sigmoid;
Reflectance Restoration Net

网络的原则是:采用较清晰的反射率作为较杂乱的反射率的参考。
损失函数:
网络结构:U-Net (更多层)
需要注意的是,为什么反射率恢复网络还要引入亮度图像,这是因为,前面说过,噪声和颜色失真最主要出现在弱光照的区域,即衰减的分布依赖于照明分布。因此,将光照信息与反射系数降低一起带入恢复网中
传统的 BM3D 会使图像出现模糊现象。而本文中恢复的方法,可保持图像的清晰和锐化。
Illumination Adjustment Net

参数:由于给定的两个图像是相对强弱的。那么,输出的图像,是以强光图像为目标呢,还是以弱光图像为目标呢?如果用户是想将弱光图像强化,就设置强光图像为目标,反之,以弱光图像为目标。这个操作可以根据用户需求而自己设置。怎么设置呢?就是通过参数来实现。其中,表示目标图像,表示原图像(例如,若对弱光图像强化,则)。
亮度调剂网络结构: two (conv+ReLu )+ one conv + Sigmoid 。注意到 被扩展为一个特征图,作为网络输入的一部分。
亮度调剂损失函数:
即输出图像应和目标图像相似,且边缘也相似。
- 与变换的对比:对比实验包括亮度降低(以弱光图像为目标)和亮度提升(以强光图像为目标)两个方面。为了更清晰说明情况,(f)-(k) 的曲线图给出了各个图像中这三列像素的曲线对比。

从 (f)-(h) 可以看出,对于亮度降低情况中,在相对明亮的区域,KinD 学习的方式在强度上比 变换减少更多,而在黑暗的区域减少较小或与 变换差不多相同。
从 (i)-(k) 可以看出,对于亮度提升情况中,KinD 方法在相对暗的区域对光的增强小于 变换,而在明亮的区域的光强调整比 变换增加更多或差不多相同。
总之,KinD 的方法在亮度调节上,比变换得到的亮度对比度更高。
- 作者最后指出,亮度调节可以通过调节实现,是参与网络训练的,被扩展为一个特征图,作为网络输入的一部分。例如,当 设置 ,表示图像的亮度增加 2 倍。